LEARN2SING: TARGET SPEAKER SINGING VOICE SYNTHESIS BY LEARNING FROM A SINGING TEACHER
Abstract
Singing voice synthesis has been paid rising attention with
the rapid development of speech synthesis area. In general, a
studio-level singing corpus is usually necessary to produce a
natural singing voice from lyrics and music-related transcription. However, such a corpus is difficult to collect since it’s
hard for many of us to sing like a professional singer. In this
paper, we propose an approach – Learn2Sing that only needs a
singing teacher to generate the target speakers’ singing voice
without their singing voice data. In our approach, a teacher’s
singing corpus and speech from multiple target speakers are
trained in a frame-level auto-regressive acoustic model and
share the common speaker embedding and style tag embedding. Meanwhile, since there is no music-related transcription for the target speaker, we utilize log-scale fundamental
frequency (LF0) as an auxiliary feature to be the inputs of
the acoustic model for building a unified input representation. In order to enable the target speaker to sing without
singing reference audio in the inference stage, the duration
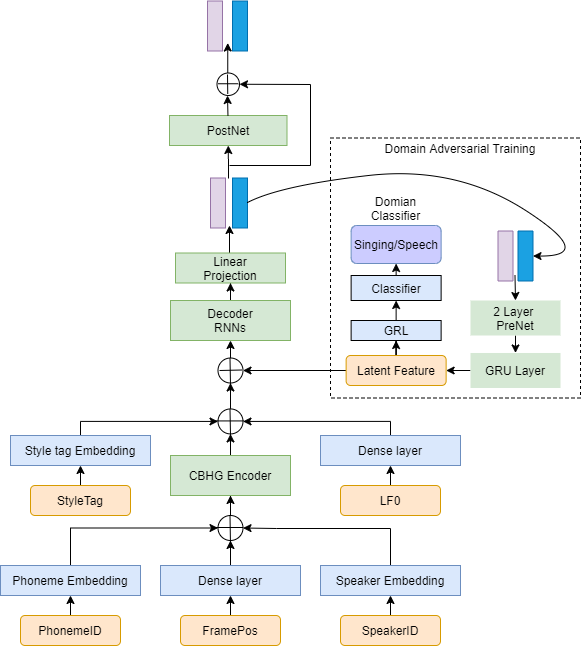
model and LF0 prediction model are also trained. Particularly, we employ domain adversarial training (DAT) in the
acoustic model, which aims to enhance the singing performance of target speakers by disentangling style from acoustic features of singing and speaking data. Our experiments
indicate that the proposed approach is capable of synthesizing singing voice for target speaker given only their normal
speech samples.
Examples of one singing teacher and two students
* Please ensure your web browser supports wav audio format.
* Student-1 is originated from an open-source corpus:https://www.data-baker.com/
* Real: real duration and LF0; Predict: predicted duration and LF0.
| Target speaker | Teacher | Student-1 | Student-2 | |||||||||||
| Test condition | Original | Synthesis | Baseline | Baseline+DAT | Reference | Baseline | Baseline+DAT | Reference | ||||||
| Real | Predict | Real | Predict | Real | Predict | Real | Predict | |||||||
| Sample 1 | ||||||||||||||
| Sample 2 | ||||||||||||||
| Sample 3 | ||||||||||||||
| Sample 4 | ||||||||||||||
| Sample 5 | ||||||||||||||